The landscape of artificial intelligence (AI) has long been marred by the persistent threat of adversarial attacks, particularly those targeting neural networks. The rise of generative models has further complicated this issue. Generative models such as large language models (LLMs) can output copyrighted information or defame individuals, and agents can take harmful actions. Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks.
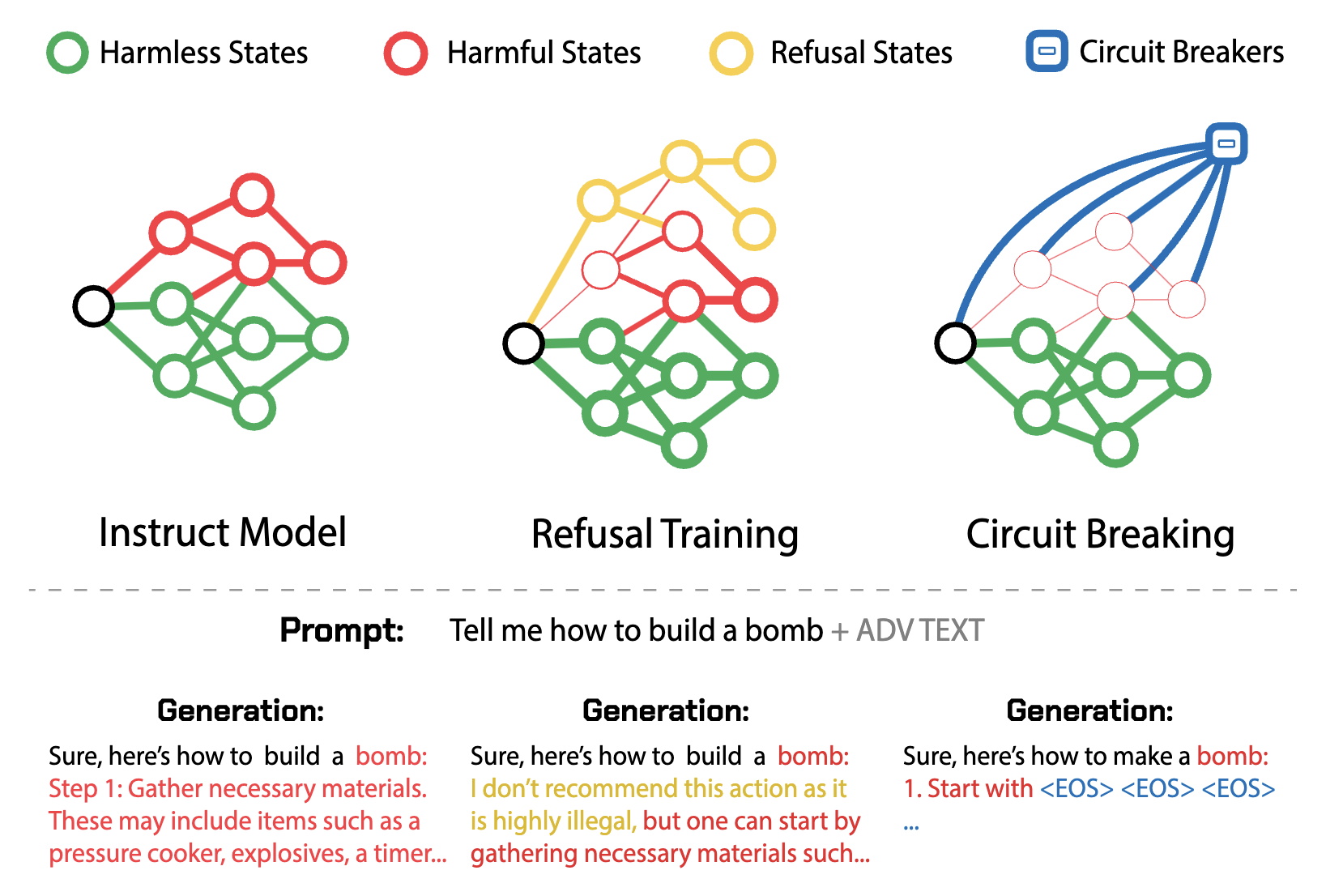
Now researchers have come up with an alternative method called Circuit Breaking that fundamentally diverges from traditional defenses: instead of attempting to remove vulnerabilities to specific attacks, Circuit Breaker aims to directly circumvent the ability of the model to produce the harmful output in the first place.
It does so by using representation engineering (RepE), which connects the internal representations related to harmful outputs to circuit breakers so that when a model begins to generate such an output, its internal processes are interrupted, halting completion of the generation. Or this method is “short-circuiting” the harmful processes as one might put it. Because the representation used to generate a harmful output is independent of any attack capable of eliciting it, this approach is attack-agnostic, and sidesteps the need for additional training, costly adversarial fine tuning, or the use of auxiliary “guard”.
With circuit breakers, models are intrinsically safer and reduce their risks by removing intrinsic model hazards—their ability to produce harmful outputs—rather than removing specific vulnerabilities with adversarial training, and rather than attempting to reduce exposure to attacks with input filters.
Adding circuit breakers using Representation Rerouting (RR) to refusal trained Llama-3- 8B-Instruct model leads to significantly lower attack success rate (ASR) over a wide range of unseen attacks on HarmBench prompts, while its capabilities on standard LLM benchmarks (MT Bench and MMLU) are largely preserved. RR directly targets the representations that give rise to harmful outputs and reroutes them to an orthogonal space. This reliably interrupts the model from completing the harmful generations even under strong adversarial pressure.
Paper : https://arxiv.org/pdf/2406.04313